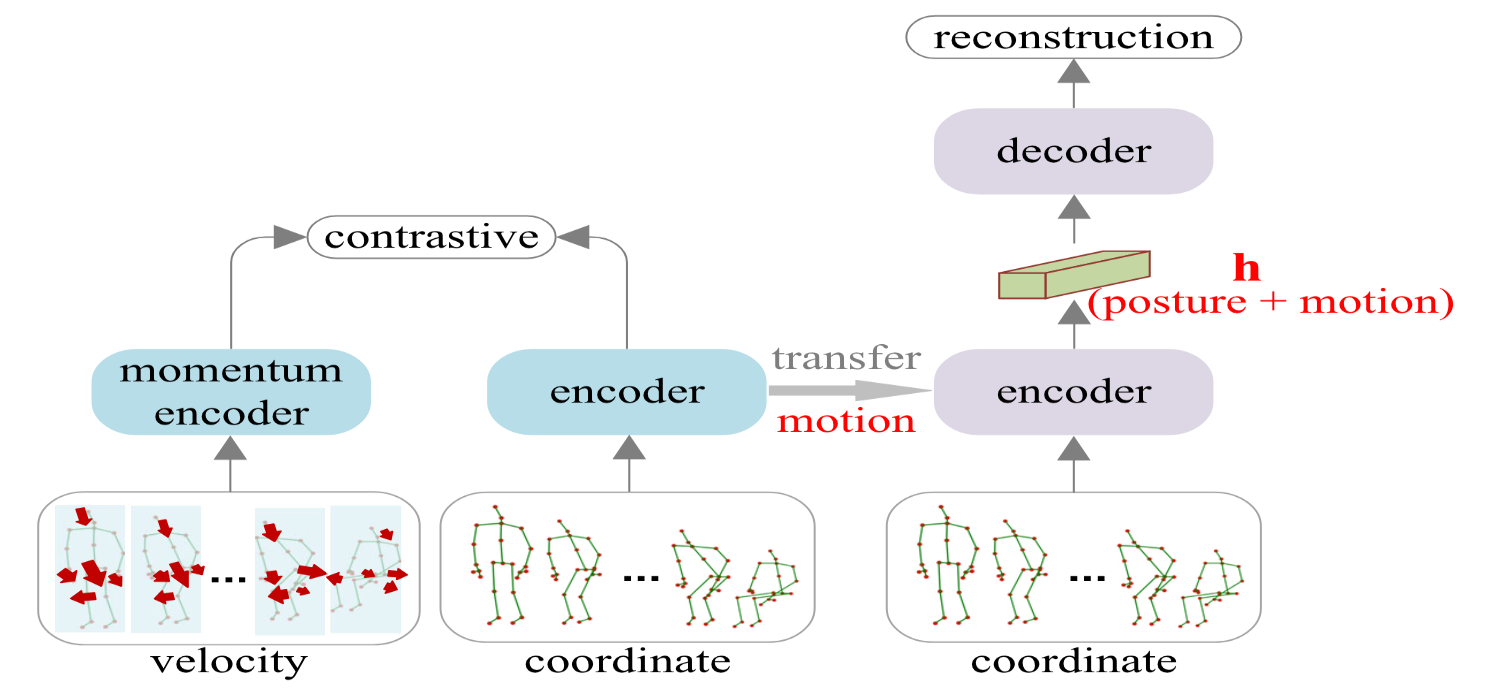
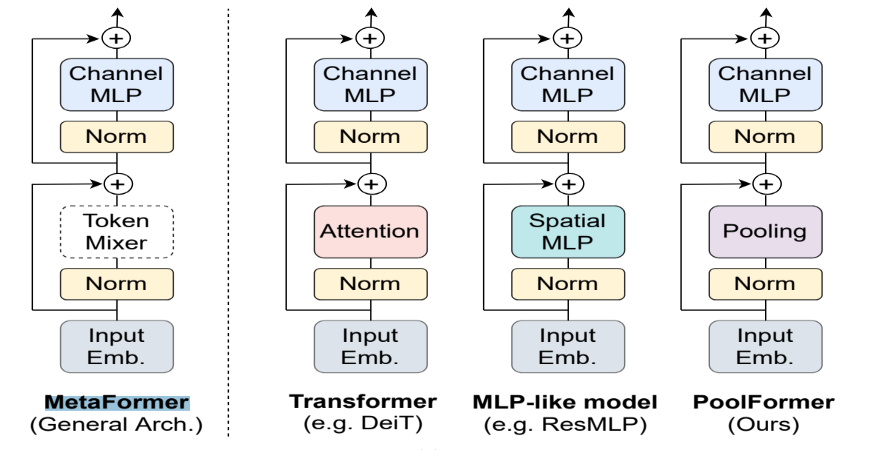
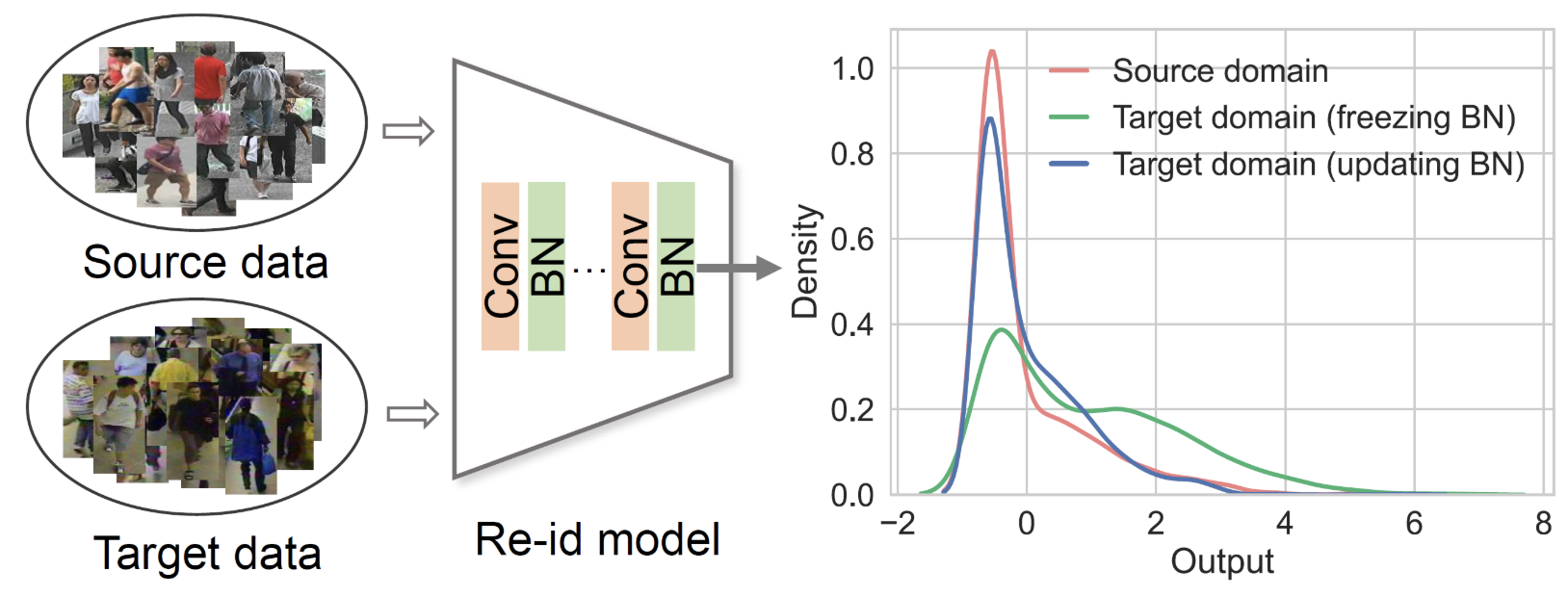
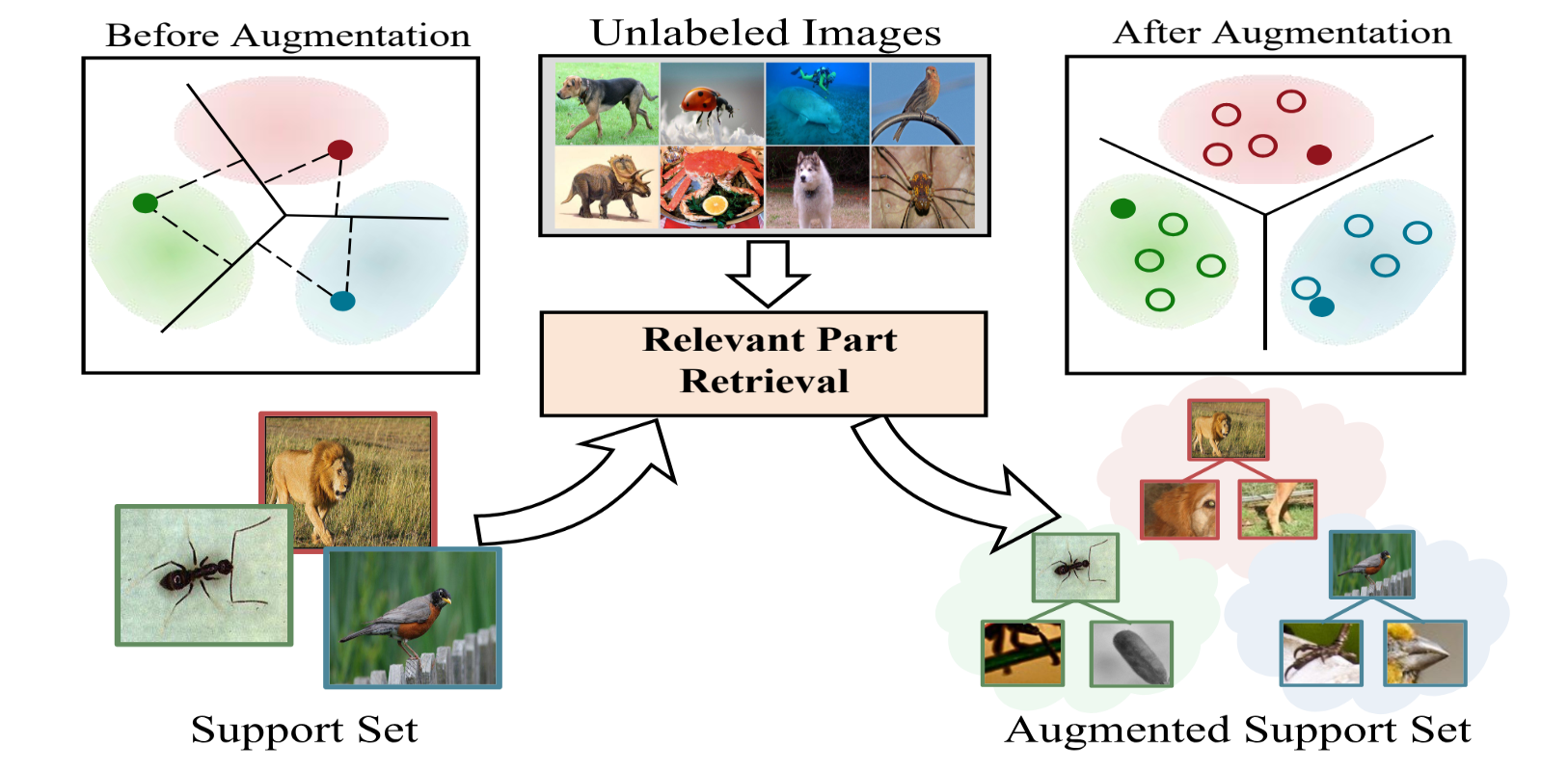
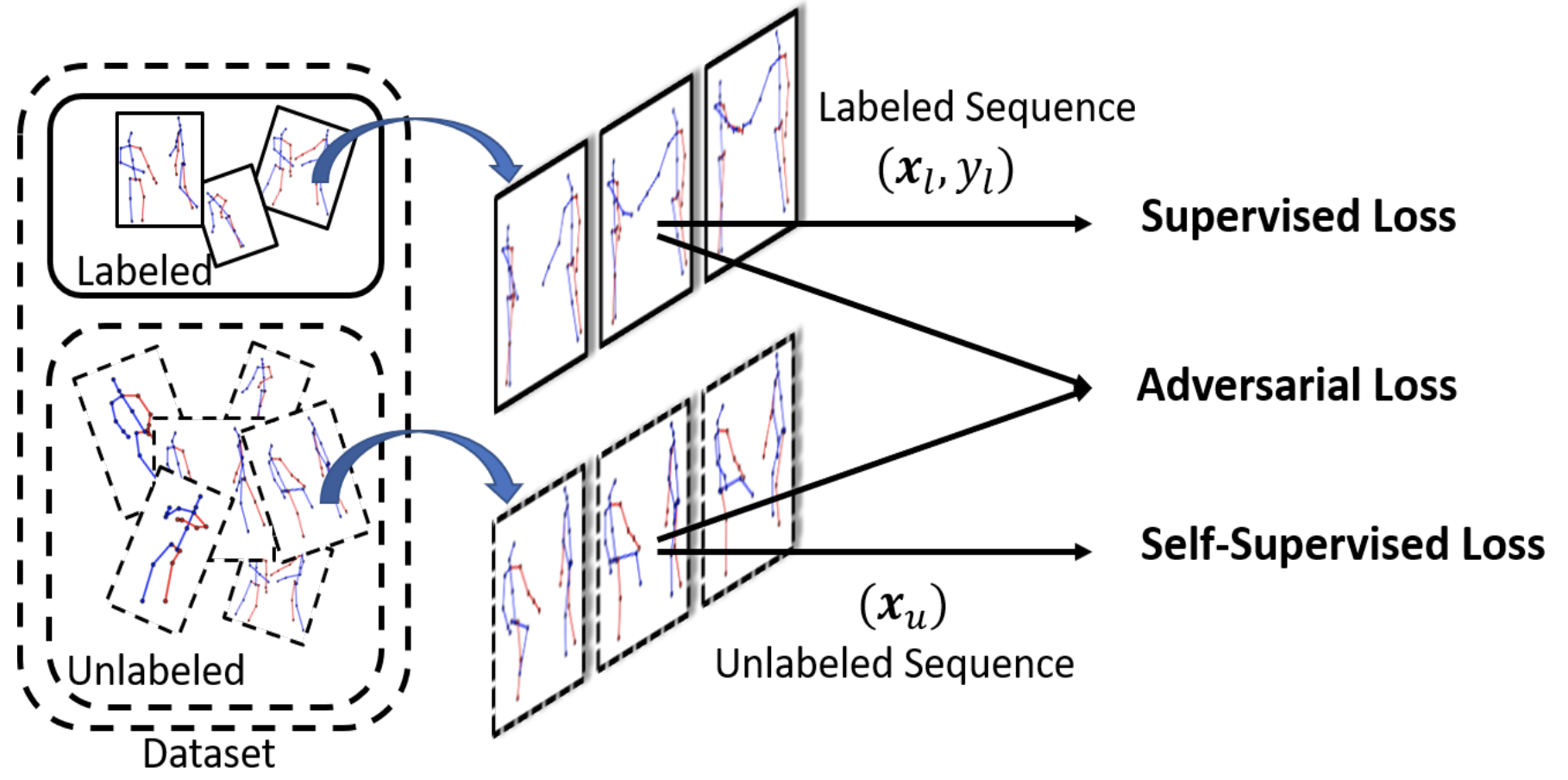
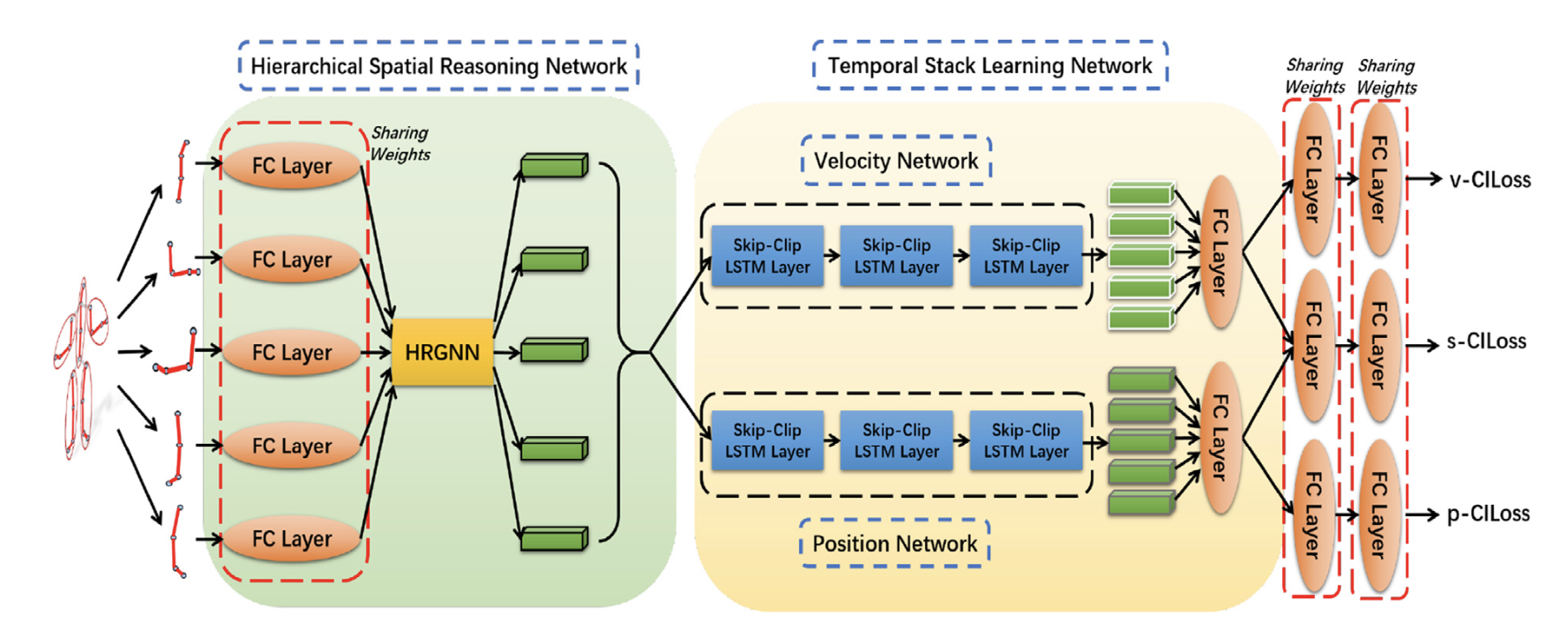
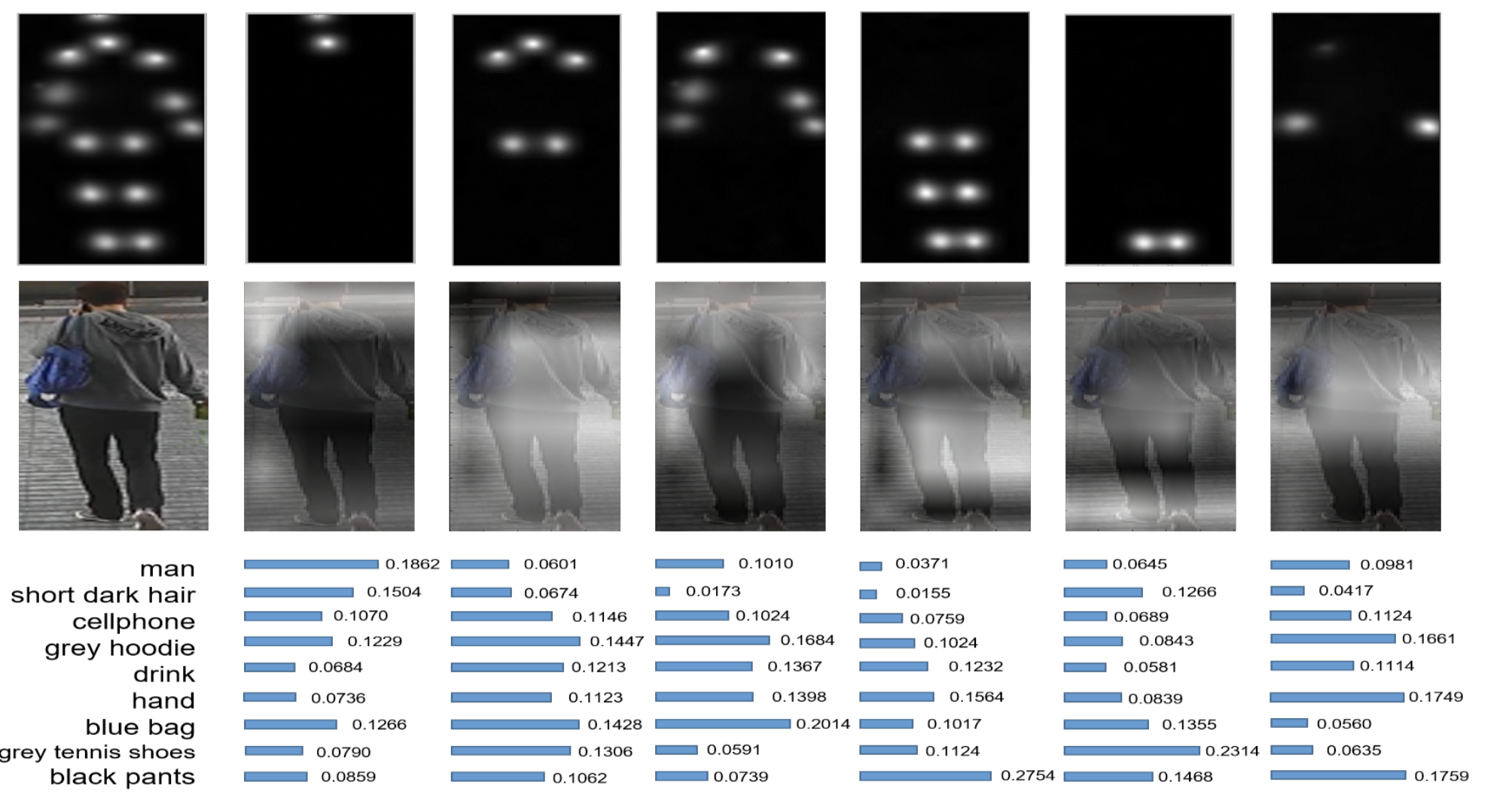
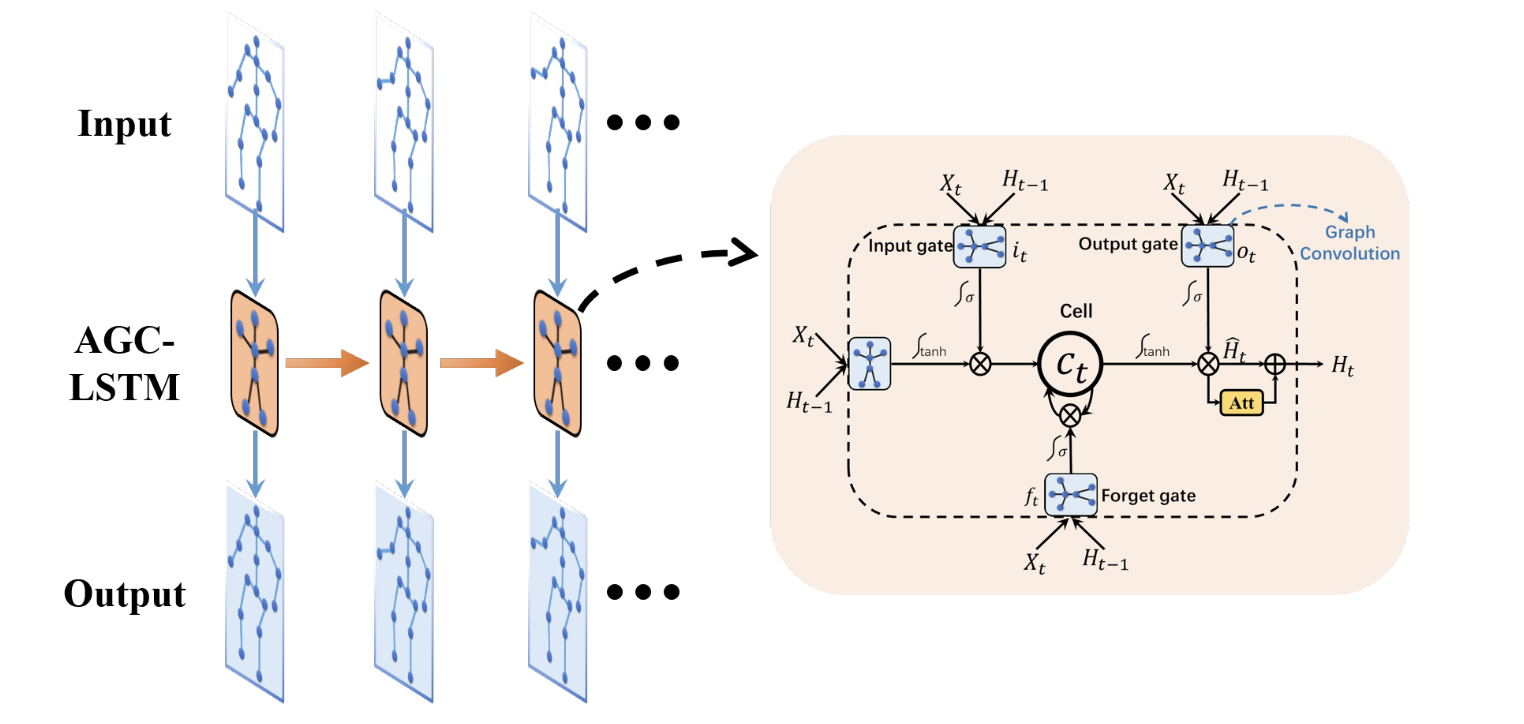
Pattern & Recongnition Lab
Chenyang Si
Associate Professor
School of Intelligence Science and Technology
Nanjing University
Nanjing University Suzhou Campus, No. 1520 Taihu Avenue, Huqiu District, Suzhou, Jiangsu
50+
Papers
7K+
Citations
5+
Members